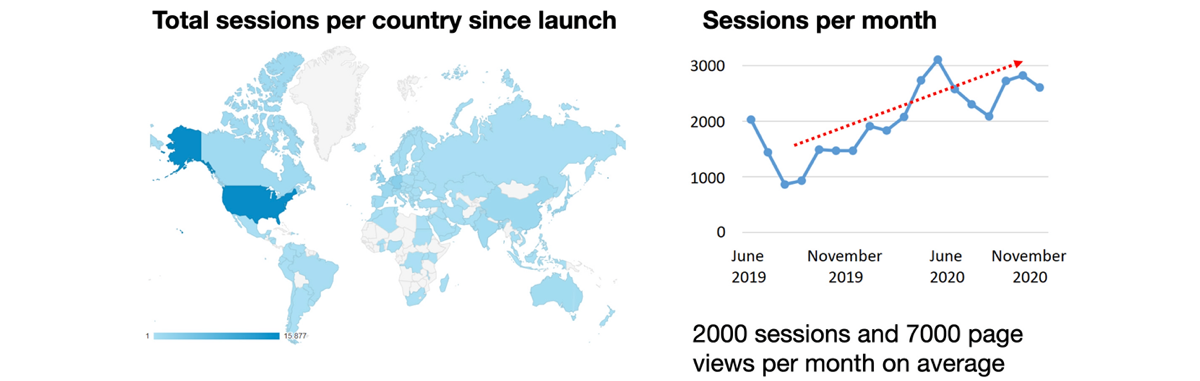
The SYNGO consortium is coordinated by the Center for Neurogenomics and Cognitive Research (CNCR) (Frank Koopmans, Loek van der Kallen, Guus Smit, and Matthijs Verhage) and brings together leading experts in synapse biology on a worldwide level to establish aknowledgebase of the synapse. In previous years, the consortium has built a new ontology for the synapse and annotated more than 1000 synaptic proteins based exclusively on published experimental evidence. Since launching the SYNGO portal and publication of the first analyses by the consortium inNeuronin 2019, the knowledgebase and portal have served many scientists worldwide, with many daily users of the portal and the Neuron paper being in the top 5% of most cited papers in the field (March 1, 2022: 195 citations in <2 years; Google Scholar).
New goals
Together with the international research community, the consortium defined several new goals. Widely recognized as the most urgent goal is the improvement of the poor current annotation of protein-protein interactions in the synapse. Large scale protein-protein interaction data are widely used, especially in -omics studies (GWAS, expression profiling, proteomics), to help interpret complex genetics signals, e.g. association of many common single nucleotide polymorphisms with human brain disease. Current data resources typically contain unsupervised annotations of protein-protein interactions based on automated text mining or high throughput assays. As a consequence, these resources contain many false positives. In recent SYNGO pilots, it was concluded that the false positive rate may be more than 50%. Several clear cases of incorrect interpretation of data due to this poor-quality annotation have been identified, also published in the most prestigious journals. SYNGO now aims to improve this situation by the curation of existing protein-protein interaction data by SYNGO’s field experts and several new partners with specific technical expertise to evaluate specific published interaction data.
Support by the Broad Institute
The Stanley Center at the Broad Institute in Cambridge, USA has generously supported the consortium from the start (Steve Hyman, Guoping Feng, and Tyler Brown) and has now decided to continue support for the next two years by its new co-director and head of therapeutics, Morgan Sheng. With the support, CNCR is employing two scientists, including dr. Frank Koopmans, SYNGO’s lead bioinformatician and architect of SYNGO’s databases & interfaces, who will coordinate the consortium and support SYNGO2 annotations and analyses.